Natural Language Processing
Primer for Encyclopedic Knowledge
- Natural Language Processing (NLP)
- Markov property
- Hidden Markov Model
- Markov Chains
- Statistical Model
Hidden Markov Models are used for probabilistic sequence classification. This model can tell us about the state sequence probabilities. In essence, the transition likelihoods between states over time, which include the likelihood of a state persisting over time (indicated by an self-referential arrow).
HMMs help to map observations to explanations of these observations, known as hidden causes/states/classes. We consider the observations to be probabilistically dependent on the hidden, unobservable component (states/classes/causes).
The figure below depicts the Conditional Probability Distribution of the next state s' given the current state s, known as the transition model P(s'|s)
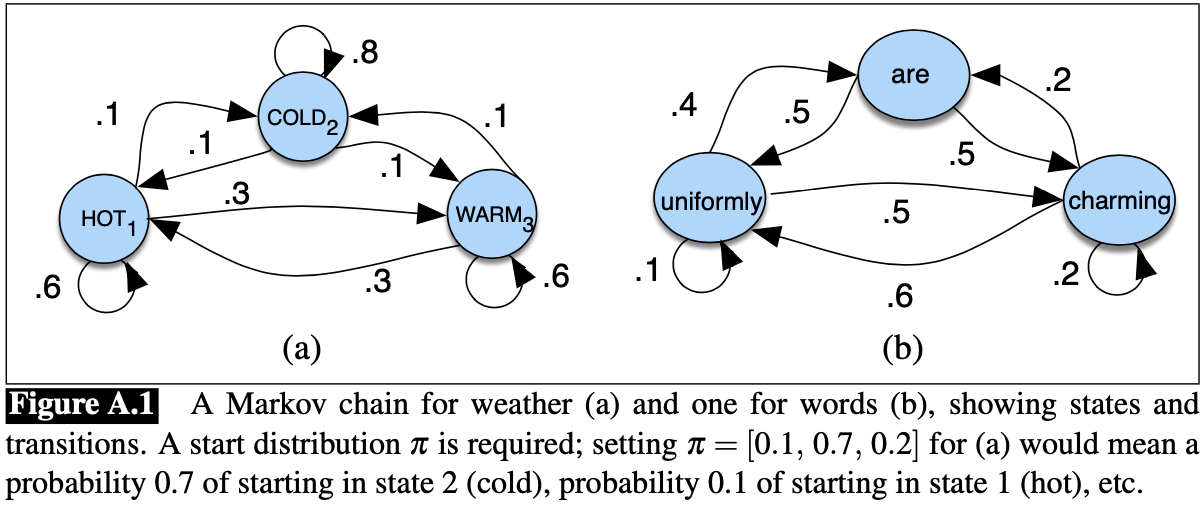
Figure from "Speech and Language Processing" by D. Jurafsky 2023.
Motivating Example: Named Entity Recognition
Named Entity Recognition (NER) is a natural language processing task that aims to identify the entities (individuals, institutions, ideas, etc.) in a given chunk of text.
The challenges are to detect the names, and then to classify them properly (e.g. detecting "Bank of America" as an entity, and then classifying it as an institutional bank, not referring to the country within the name).
Some background topics:
- Formal grammar; Formal language
- Information Extraction
- Knowledge Extraction
- Ontology
- Information Science
We love NLP!
Noun, Verb, Pronoun
Using Part of Speech Tagging (POS) is sequentially labelling the words by their part of speech. If we collect enough data on the underlying part-of-speech sequences, we can get a good idea for the patterns behind sentences.
How are Hidden Markov Models used in named entity recognition?
Sequence Modeling: We don't know the (hidden) parts-of-speech for the sequence of words, a.k.a. our sentence, but we can see the words (observations). The named entity tag (eg. Person, Organization, etc.) is, like the part of speech, considered the hidden state. The sequence of words in a sentence forms the sequence of observations, and the corresponding sequence of named entity tags forms the hidden state sequences.
Training the Model: Through a well-labeled corpus of text, we train the model with a labeled dataset to get it familiar with some of the sequential patterns:
- Transition Probabilities: the likelihood of change between states: probability of going from a 'person' tag to a 'organization' tag. This is learned initially from memory of the training labels.
- Emission Probabilities: The probability of a particular word being observed given a particular entity tag as evidence.
- Initial Probabilities: Represents the likelihood of seeing a particular tag at the start of a sequence.
Decoding with Viterbi
Decoding: Once trained, the HMM can be used to predict the most likely sequence of hidden states (entity tags) for a new sequence of observations (words in a sentence). This is typically done using algorithms like the Viterbi algorithm, which efficiently finds the most likely sequence of hidden states based on the observed data and the model’s parameters.
- Objective: The Viterbi algorithm finds the most probable sequence of hidden states given a sequence of observations. In NER, this translates to identifying the most likely sequence of tags after observing a sentence.
- Process:
- Iteration: For each subsequent word (observation) in the sentence, calculate the probability of each state (tag) by considering:
- The probability of transitioning from each of the previous states to the current state.
- The emission probability of the current observation (word) given the current state.
- Multiply these probabilities and select the maximum probability for each state.
- Path Tracking: Keep track of the path of states that led to these maximum probabilities.
- Termination: After processing all observations, the path with the highest probability is chosen as the most likely sequence of states (tags).
The Viterbi algorithm effectively navigates through the exponential number of possible state sequences to efficiently find the most probable sequence.
Understanding Hidden Markov Models (HMMs)
Hidden Markov Models are a staple in probabilistic sequence classification, particularly used in the context of Natural Language Processing (NLP) for tasks like Named Entity Recognition (NER). They serve as a powerful tool for modeling the probability distributions of sequences, providing a framework for understanding the sequential data by relating observable events to hidden states.
Application in Named Entity Recognition
NER is an NLP task where HMMs are utilized to identify and classify named entities—like people, organizations, or locations—in text. The complexity of language makes NER a challenging problem. HMMs address this by allowing us to statistically model sequences of words and the corresponding entities they represent, even when these entities are not explicitly mentioned.
The Viterbi Algorithm: Decoding the Hidden States
The Viterbi Algorithm is a dynamic programming approach to decode the sequence of hidden states in an HMM. This algorithm calculates the most likely sequence of hidden states given a sequence of observed events. It does so efficiently by recursively determining the maximum probability of any sequence that ends at each state, using the transition probabilities between states and the probabilities of observations given states.
As an integral part of the HMM framework, the Viterbi Algorithm's ability to find the most probable path through the state space is crucial for applications like speech recognition, handwriting recognition, and of course, NER.
Training HMMs: The Forward-Backward Algorithm
Training an HMM involves learning the model's parameters—the state transition probabilities and the observation emission probabilities. The Forward-Backward Algorithm, also known as the Baum-Welch Algorithm, is a special case of the Expectation-Maximization algorithm used for this purpose. It iteratively improves the model's parameters by computing forward and backward probabilities and re-estimating the transition and emission probabilities to maximize the likelihood of the observed sequence.
Visualizing HMMs and the Viterbi Algorithm
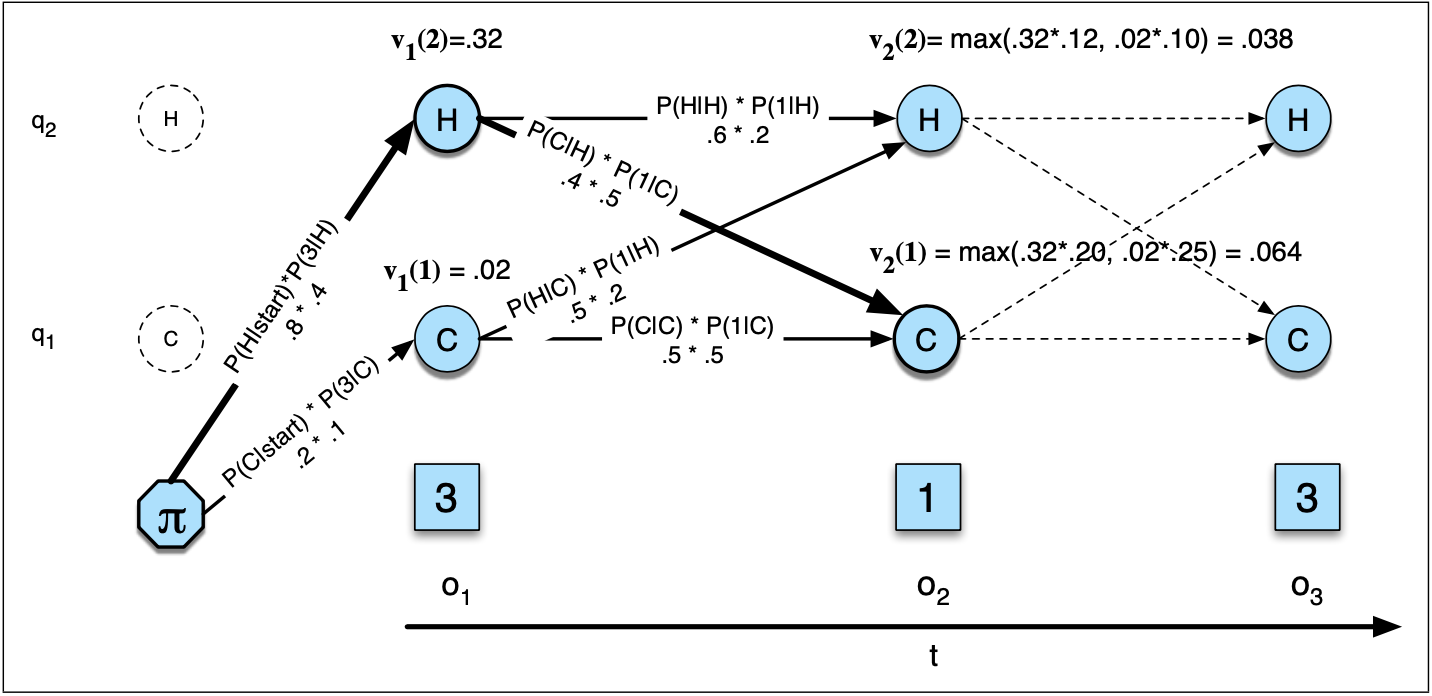
Figure: Viterbi trellis illustrating the computation of the most likely path through the hidden states.

Figure: The Forward-Backward Algorithm for training Hidden Markov Models.

Figure: The Viterbi Algorithm for decoding Hidden Markov Models.
It should be noted that the algorithms and models covered in this page are not the best
Where do these matrices lead?
The transition matrix on this page — a row-stochastic P(s'|s) — is the very same object that Donald Hoffman & Chetan Prakash use as the literal substrate of a conscious agent. In their program a Hidden Markov Model is simply a trace chain with one restriction removed (the HMM's one-way hidden→observed causation), and the act of observation becomes a precise operation — the trace — that induces a non-Boolean "trace logic" on the space of all Markov chains.
The companion page rebuilds the whole arc from first principles, with every claim tagged by how much we actually know — textbook math, proven theorems, the authors' conjectures, and reasonable extrapolations.